 If you want to process Open Data automatically you have top think about form and content of the data (syntax and semantics). The popular data portals of municipalities, states, federal level in Germany or EU the as govdata.de open data sets are stored in different formats (PDF, CSV, JSON, etc.) without any given structure related to the content. To get an idea of the content of the data mostly a tagging is conducted with „metadata“. This is useful for human beings (like working with catalogues in libraries in ancient times) but nor for machines. About the contentual structure of the data is nothing said. For example, what is a kindergarten, a day nursery, a child-care institution? With what data or links to information can we describe a kindergarten? In this article a suggestion is made how we can make the data accessible for processing with a machine with the help of a Semantic Web so that e.g. automatic updates are made possible with a standardization of the content.
If you want to process Open Data automatically you have top think about form and content of the data (syntax and semantics). The popular data portals of municipalities, states, federal level in Germany or EU the as govdata.de open data sets are stored in different formats (PDF, CSV, JSON, etc.) without any given structure related to the content. To get an idea of the content of the data mostly a tagging is conducted with „metadata“. This is useful for human beings (like working with catalogues in libraries in ancient times) but nor for machines. About the contentual structure of the data is nothing said. For example, what is a kindergarten, a day nursery, a child-care institution? With what data or links to information can we describe a kindergarten? In this article a suggestion is made how we can make the data accessible for processing with a machine with the help of a Semantic Web so that e.g. automatic updates are made possible with a standardization of the content.
Introduction | Semantic Web | Open Data | Application in Tourism | Application in Social Entities of Municipalities | Future Work
Introduction
In the last few years the Open Data movements gathered speed. What it is all about I described in the article Open Data: the next round and Open Data Institute (ODI): Open Data in a Day (German ;-).
In the beginning activities where focussed on data of the public service which were already there to make them available for a second usage. If you look at a modern transparency law (or freedom of information act) like the City of Hamburg which is also a state) introduced it in 2012 (German) where data a) are to be held electronically as default (electronic file) and b) always have to be published electronically (as long as they do not contain personal data as of privacy or safety-critical data) the question rises quickly in what format they hav to be published. Therefore Tim Berners-Lee developed a five star capability maturity model:
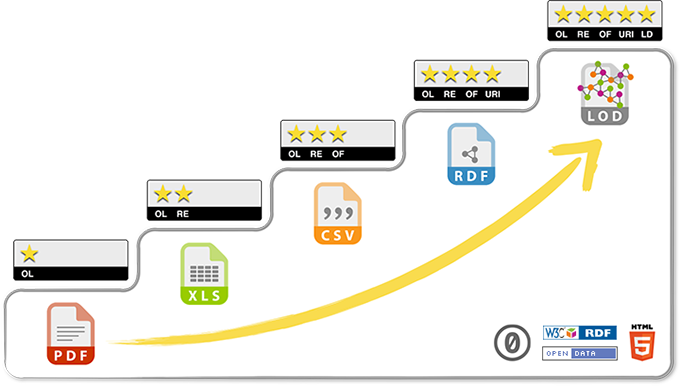 Figure 1 Five star capability maturity model after Tim Berners-Lee
Figure 1 Five star capability maturity model after Tim Berners-Lee
A PDF-file is marked with one star (e.g. minutes of a council session). Two stars are given for an Excel-file: it is structured but has a proprietary format. More open is a CSV-file (Comma Separated Value) with three stars. Four stars get data in the RDF-format (Resource Description Framework). On the one hand you will find here informations where a resource can be found. On the other hand there the first steps to a semantic approach. It it defined what is to be talked of. Full five stars are for a data set with Linked Open Data.
Here we have than data (instead of pure HTML-texts) which are linked in the Internet, are retrievable via HTTP, use mechanisms like RDF and SPARQL (a query language) as well as the Web Ontology Language. This enables a processing of Open Data by machines and not only by human beings.
A simple example shall illustrate this. If you publish in public transport schedule and actual data in real time via an API (application programming interface) then you have to standardize the content. You need an ontology (What is a schedule? What is a station (geographically)?) and a taxonomy (How are the data structured? What is the syntax?). This has been done with the international standard GTFS (General Transit Feed Specification). With GTFS you can put the schedule and the actual data with an API online and other machines can use these data for applications (e.g. for routing: how can I get from location A to location B). In the United Kingdom this was done successfully by the company TransportAPI:
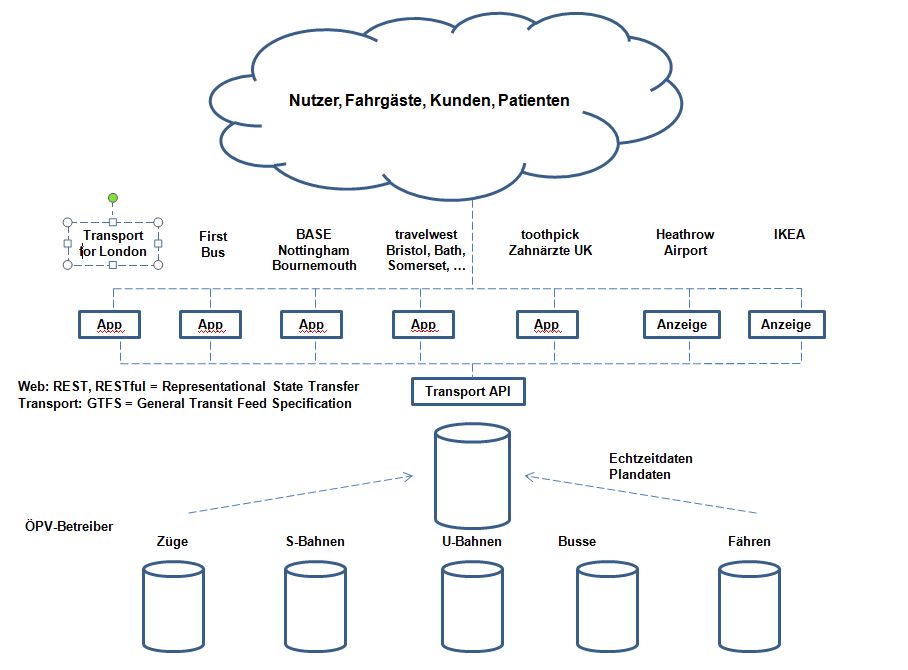 Figure 2 Flow of data at TransportAPI in London, UK
Figure 2 Flow of data at TransportAPI in London, UK
As a class diagram you can outline GTFS as follows:
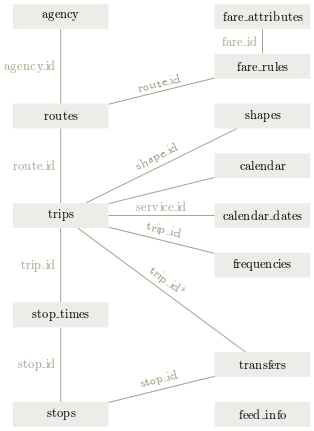 Figure 3 GTFS as class diagramm (public domain after Wikipedia)
Figure 3 GTFS as class diagramm (public domain after Wikipedia)
In the following it will be discussed what semantic webs are and what they have to do with Open Data. Examples from applications in tourism and social entities will illustrate the problems pragmatically. At last it is discussed what needs to be done.
Semantic Web
The classic web was defined by three important standards with which Tim Berners-Lee introduced the World Wide Web:
- URLs (Uniform Resource Locator) for the addresses of any files in the Internet
- HTTP (Hypertext Transfer Protocol) as a protocol to download these files and
- HTML (Hypertext Markup Language) as a markup language for text documents.
With these access, transport and text format are defined, but not the content or the meaning.
Time Berners-Lee completed those standards with his suggestion for a semantic web, where also an ontology and a taxonomy is defined. Formally the architecture stack of standards looks like in this figure:
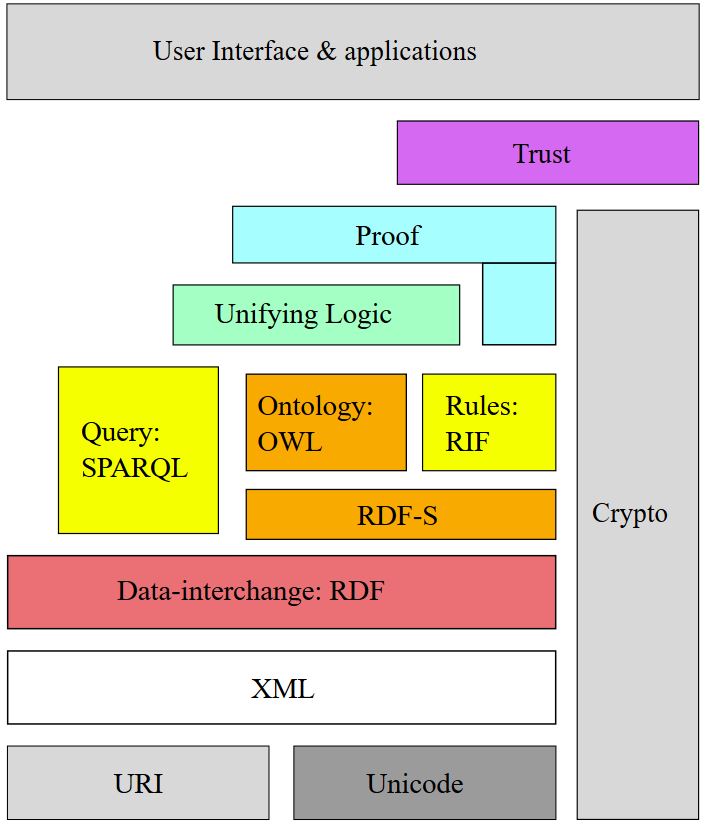
Figure 4 Semantic Web (Author: Von I, Mhermans, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=2291674)
Top down the following elements are standardized (see Wikipedia):
- URIs in the double role for identifying entities and for pointing to further data (Linked Open Data) with RDF as a common model for representation of Propositions
- RDF-Schema for declaration of a vocabulary which uses RDF
- OWL for a formal definition that in the RDF-Schema declared vocabulary in a dedicated ontology
- RIF for the exposition of rules
- SPARQL as query language and query protocol
- some different syntaxes to exchange RDF-graphs:
These kinds of semantic webs have found their way into business applications and are spread in research of universities, but not yet in Public Service.
Open Data
For Open Data of the Public Service (Open Government Data) normally there are no ontologies yet. Especially the velocity in Germany is rather small. Following the five-star-modell of Tim Berners-Lee we are talking about four stars (RDF – Resource Description Framework) and five stars (LOD – Linked Open Data).
In the public service we will find frequently machine-readable Open Data as an Excel-file (*.xls, *.xlsx) or as Comma-Seperated Value (*.csv). To exploit the content some people tend to tag it as it was done in former times in libraries with books and to keep a card index which is connected to the objects (files) but not with the content. Already daycare facility for children have no unambiguous identifier: day nursery, kindergarten, day care center, play school, preschool, etc. Additionally there is no ontology which attribute or feature create a kindergarten (postal address, geographic coordinates, pedagogical concept, catering, rooms, assessment by parents, costs for parents, staffing and so on (see also my article Open Data: the next round).
This is not to suggest ontologies and taxonomies for the public service (now) but only to examine two examples to trigger a discussion: tourism and social entities (like kindergartens, schools, etc.).
Application in Tourism
The University of Florence, Italy, conducts a complex semantic web project km4city. The following figure shows the used elements in an overview. Details can be explored on their website.
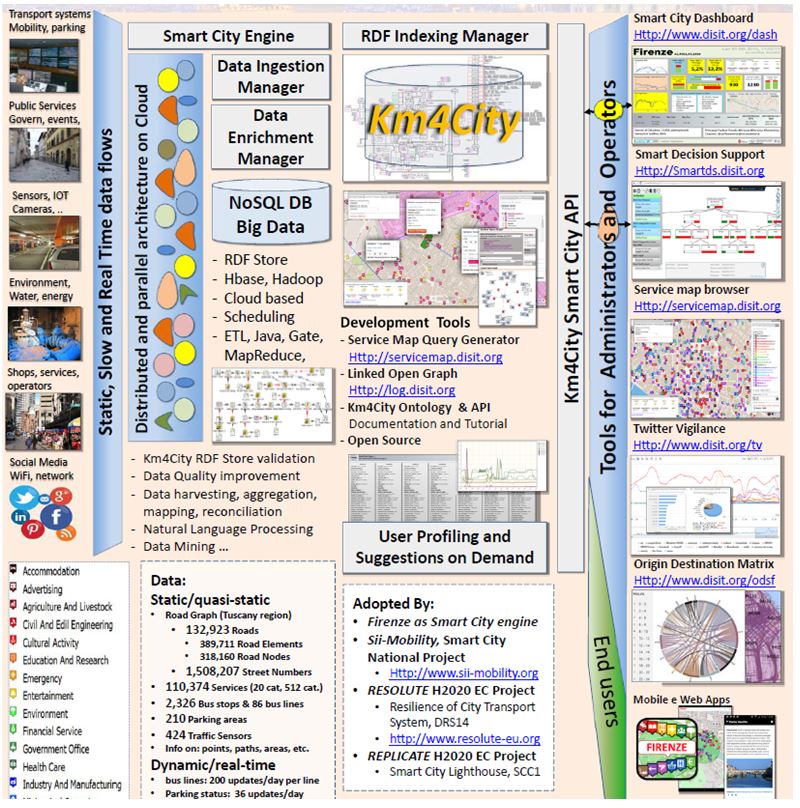
Figure 5 Project km4city, Florence, Italy
One part of the project is a map (Open Street Map) where a lot of entities are shown on different layers. Through a menu you can choose what kind of objects shall show up. One speciality is that you can look for public traffic connections as in Google Maps. A tourist can plan his stay by picking up objects to visit an then can look for connection e.g. from the main station to the Duomo (cathedral) or to the townhall or to the Uffizi or to the south bank of the River Arno (but there is no bus over the Ponte Veccio 😉
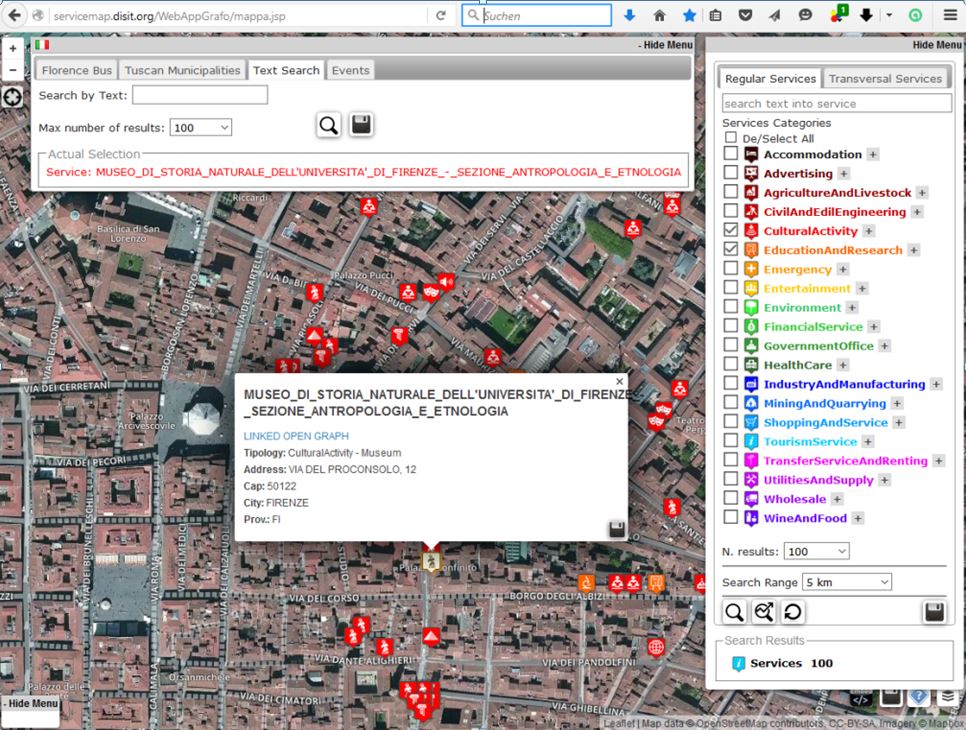 Figure 6 Map from the project km4city (Online-Source look here)
Figure 6 Map from the project km4city (Online-Source look here)
But the depth of detail is not that large. Take for example the Florence Cathedral of Florence (Duomo) you will not learn:
- that this masterpiece of art was build in the renaissance (and just not from the Gothic period (See my German articles from the Gothic period :-)
- that the dome (cupola), the main work of Brunelleschi, is a spectacular building
- that Niccolo Macciavelli (see picture above), Dante Alighieri, Petrarca, the family of Medici and others shaped the city intellectually and
- that Dan Brown used in his crime novel „Inferno“ the Duomo in Florence as playground (see also the film on YouTube or the FAZ-article (both German) on „Crime-Novel-Tourism“).
So here we have to set up an ontology and a taxonomy: what is a cathedral? Which attributes do describe it (architecture, features and furnishing, history, literature, see also the article about Notre-Dame de Paris and The Hunchback of Notre Dame) ? Will the taxonomy and a universal graph allow a query like this: „Which superb edifices does Dan Brown describe in his novels e.g. in Rome, Florence and Istanbul?“?
The Book I’m Off Then of Hape Kerkeling which was also adapted in a film brought the Way of St. James or Camino de Santiago (in German Jakobsweg) a renewed tourist attraction for catholic pilgrims. The end is in the West in Santiago de Compostela in Spain. But in the East more and more regions want to profit from fame so it gets longer and longer. So cities and villages which are touched by the way are encouraged to provide informations for the tourists so that you can quickly find places of interest, restaurants, accomodations and even public transport facilities. To prepare such a map with Goople Maps takes only few hours. This example in the figure is taken from my article (German) and shows a village on the left Lower Rhine (my home village ;-).
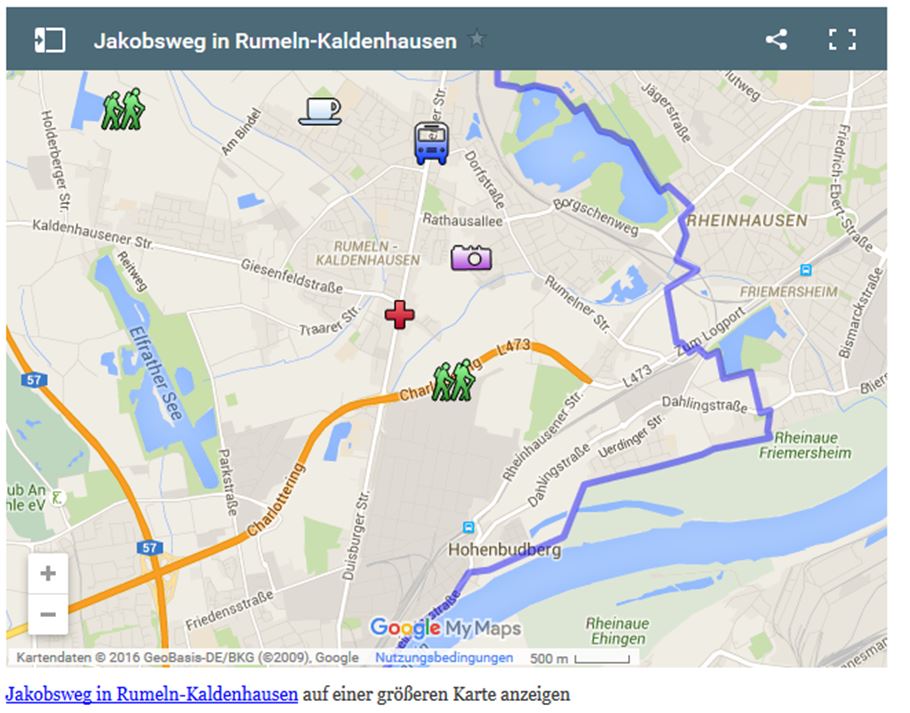 Figure 7 Way of St. James (Jakobsweg) in Rumeln
Figure 7 Way of St. James (Jakobsweg) in Rumeln
But here also ist the question for ontology and taxonomy for the object to show. With what should the markers on the map be attributed, for example a restaurant: address, geographic coordinates, telephone, website (with menu card), photos, opening hours?
The next figure shows a restaurant in Rumeln-Kaldenhausen with a photo from the 1970th if you click on the coffee cup (or tea cup for the British :-). It should be also mentioned that with Google Maps (and Microsoft Bing Maps) in principle you can export these data with KML to aggregate the data from different maps. On the other hand it is very simple to maintain the data of the maps with Excel (or equivalent), to upload them to Google Maps for creation of a map and to embed this map in your content management system.
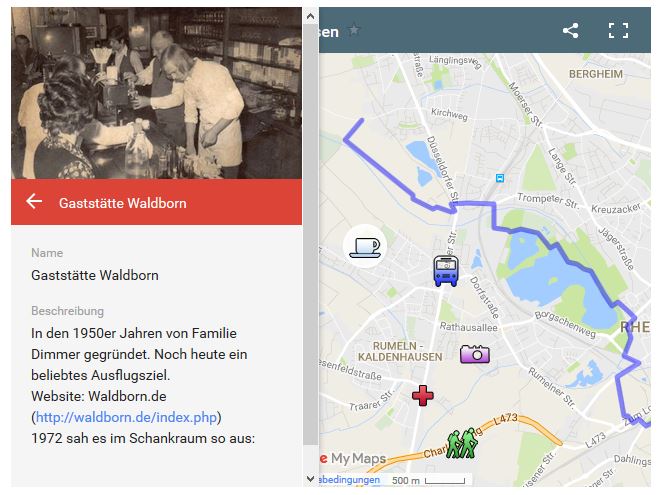 Figure 8 Gaststätte in Rumeln
Figure 8 Gaststätte in Rumeln
You may think for example of a tourism entrepreneur who wants to offer all-inclusive packages for pilgrims who will be interested in stardardized data all along the way not only of one village. Here will be also a demand for internationality because the way leads through Germany, France and Spain. Tourism is a scenario to aggregate data which exist always in another context. Other scenarios you may find with social entities.
Application in Social Entities of Municipalities
Scenarios can help to explore better the benefit of activities. E.g. a relocation scenario for a family or a scenario for the establishments of businesses (see also the ‚points of single contact‘ service directive of the EU)
If for example a family with two children (five and nine years old), two parents and a grandfather relocate there always information demands which can be covered by existing data of the public service in most cases. The listing below shows object for which the family data needs but for which up to now no ontologies and taxonomies exist. Despite the high numbers of relocations in a mobile society.
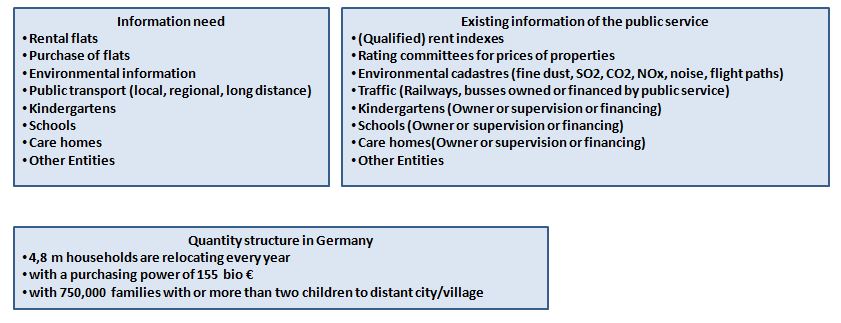 Table 1 Objects of Information need, existing information and quantity structure
Table 1 Objects of Information need, existing information and quantity structure
The City of Bonn has for example in their Open Data portal a CSV-file with Kindergartens. Within a very short time it can be uploaded to Google Maps and displayed as a map, where the marker can be clicked for further information:
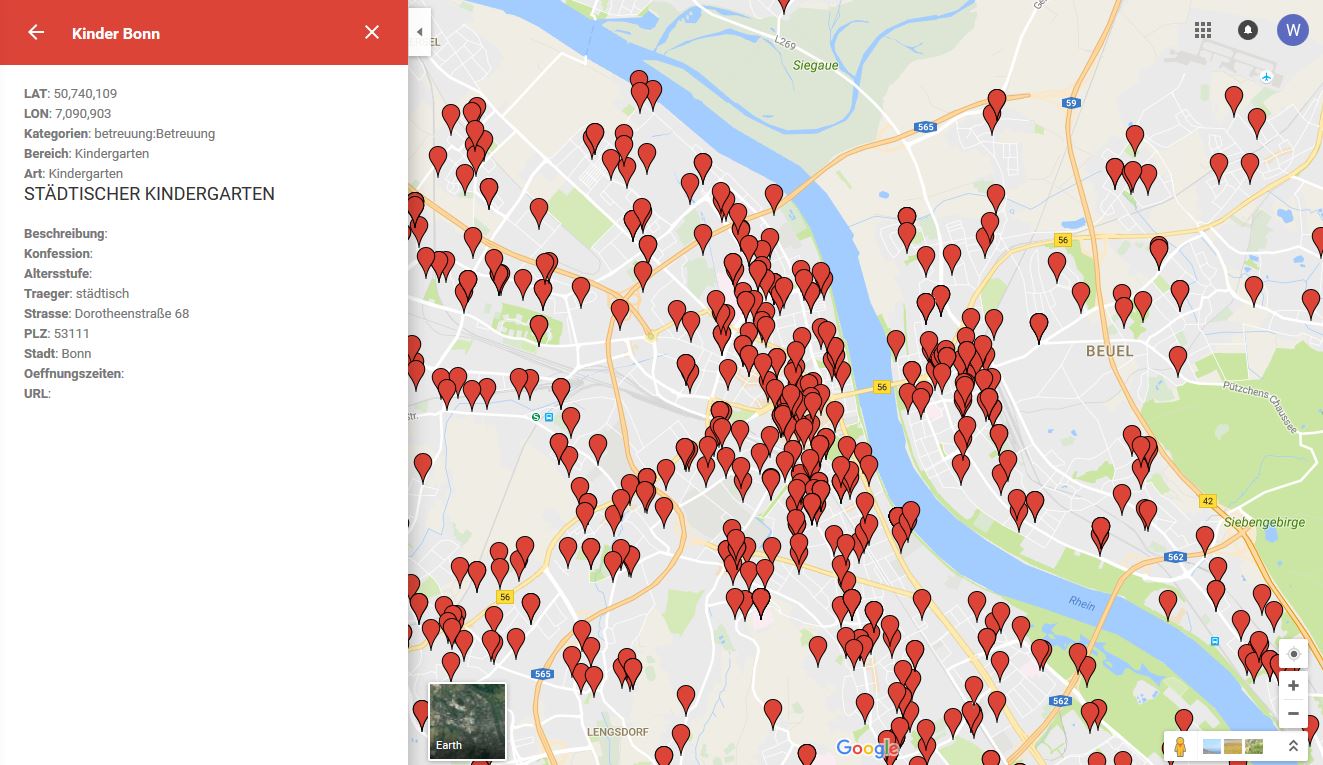 Figure 9 Kindergartens Bonn
Figure 9 Kindergartens Bonn
The advantage of a map is for the above scenario of a family relocation is that the question which kindergarten is „in the near“ of the flat can be answered more easy than with a list. Because in the scenario was looked also for a school and a care home it would be helpful to have selectors like in the Florence map to activate kindergartens, schools, care homes one after the other on the same map.
If the village is not that large perhaps all objects can be placed one one map without selectors as you can see in the following figure from the demonstration example out of the article „Google Maps mit Rumeln“ (German), as it was used also in the article „Mehr Nutzen für Bürger und Wirtschaft – nicht nur beim eGovernment“ (German) in the newspaper eGovernment-Computing.
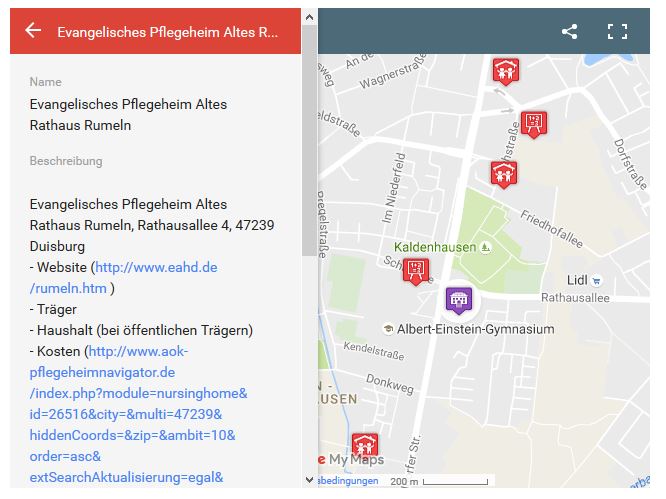 Figure 10 Social facilities in Rumeln-Kaldenhausen (Duisburg)
Figure 10 Social facilities in Rumeln-Kaldenhausen (Duisburg)
The benefit of such maps can be summarized:
Benefits for the citizen (which is similar to the business)
- The citizen can access with a simple user interface (map or WWW) Open Data of the public service
- Geographical information must not be searched in different systems
- For relocations and for permanent residents the informations in the neighbourhood are close together
- All information which the public service with a lot of effort gathers can be reused for additionally purposes
- The transparency avoids false investments, e.g. purchase of a house with an excessive price
- With transparency you can choose the „right“ entities (take the example that one year repition in a school might cost a 100,000 € because you have one year less to work in your lifetime)
Benefits for the public service
- Villages and cities can expose their attractiveness directly in their own portal and with providing e.g. KML-files they can extend their reach by other aggregators
- By the usage of hyperlinks sources of information can be integrated without buildung own applications
Besides the yet described objects where the public service has a lot of data which can be reused in additional contexts lets say a word about environmental data. Think of the upcoming Internet of Things (IoT) where we can see now sensors in a lake near Bangalore, India, for sulphate, phosphate, pH-value, temperature, oxygen content where the produced data are published on a website. The amount and categories of data are growing fast which can be used as Open Data for different purposes.
The last example shall schwo what happens if the Open Data Community does achieve nothing of value. The figure shows the output of Google Maps which comes up for the input „Kindergarten Manhattan„. This comes up in a German context. A lot of objects are found which are not all Kindergartens but there still Kindergartens also. With photo, address, website, possibility to explore any object within of Google Streetview. If all Villages and Cities will do nothing they will get dependent of Google that parents find there what they are looking for. Is your village, your city there presented right? Googles Artificial Intelligence is leading edge and very advanced, but with defined standard in semantic webs we can get even beyond that.
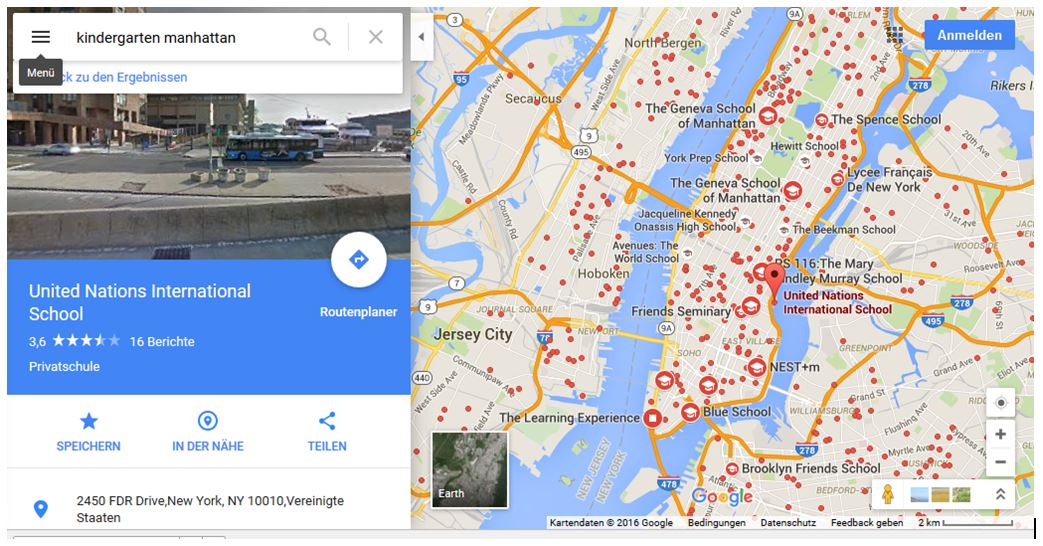 Figure 11 Google Maps Suche „Kindergarten Manhattan“
Figure 11 Google Maps Suche „Kindergarten Manhattan“
Future Work
So in the future we have to create semantic standards to present Open Data in semantic webs also so that even machines can operate these data. Websites with unstructured data in Excel- or CSV-format are not enough. So look as a reminder on what Martin Kaltenböck from Vienna expressed yet in 2013: eGovernment Konferenz 2013, Österreich – Workshop: Grundlagen und Mehrwerte von Linked Open Data (LOD)
 Figure 12 What is a Kindergarten?
Figure 12 What is a Kindergarten?
Here is now a table for the entities kindergarten, school and care homes with data which are known to the public service which be published as Open Data to give the citizen more benefits with data where he ha paid the creation already with his taxes.
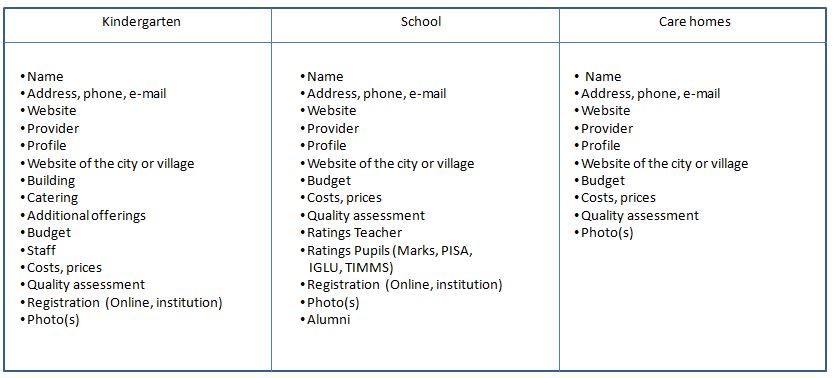 Table 2 Attributes of kindergartens, schools and care homes
Table 2 Attributes of kindergartens, schools and care homes
The exciting question is how we can structure and standardize the attributes so that these classes of Open Data are usable in semantic webs and can be operated by machines.
Who is interested to work on these things or wants to finance such work is invited to contact me (wk@wolfgang-ksoll.de). The five stars of Tim Berners-Lee must come. Who should do it: If Not Us, Who? 😉