 Wenn man Open Data automatisiert verarbeiten will, muss man sich Gedanken um die Form und den Inhalt der Daten machen (Syntax und Semantik). In den gängigen Datenportalen der Kommunen, Länder, der EU oder des Bundes wie govdata.de werden Open Data Datensätze abgelegt in unterschiedlichen Formaten (PDF, CSV, JSON, etc.) ohne inhaltlich vorgegebene Struktur. Um die Datensätze inhaltlich erschließen zu können, wird meist eine Verschlagwortung mit Metadaten durchgeführt, die nur Menschen, nicht aber Maschinen nutzen können. Über die inhaltliche Struktur der Daten wird damit aber nichts gesagt. Was zum Beispiel ist ein Kindergarten, eine Kindertagesstätte, eine Child-Care-Einrichtung? Mit welchen Daten oder Links auf Informationen lässt sich ein Kindergarten beschreiben? Hier soll nun ein Vorschlag gemacht werden, wie mit Hilfe eines semantischen Webs Open Data auch inhaltlich maschinell zugreifbar gemacht werden, so dass über die inhaltliche Standardisierung hinaus auch automatische Updates möglich werden.
Wenn man Open Data automatisiert verarbeiten will, muss man sich Gedanken um die Form und den Inhalt der Daten machen (Syntax und Semantik). In den gängigen Datenportalen der Kommunen, Länder, der EU oder des Bundes wie govdata.de werden Open Data Datensätze abgelegt in unterschiedlichen Formaten (PDF, CSV, JSON, etc.) ohne inhaltlich vorgegebene Struktur. Um die Datensätze inhaltlich erschließen zu können, wird meist eine Verschlagwortung mit Metadaten durchgeführt, die nur Menschen, nicht aber Maschinen nutzen können. Über die inhaltliche Struktur der Daten wird damit aber nichts gesagt. Was zum Beispiel ist ein Kindergarten, eine Kindertagesstätte, eine Child-Care-Einrichtung? Mit welchen Daten oder Links auf Informationen lässt sich ein Kindergarten beschreiben? Hier soll nun ein Vorschlag gemacht werden, wie mit Hilfe eines semantischen Webs Open Data auch inhaltlich maschinell zugreifbar gemacht werden, so dass über die inhaltliche Standardisierung hinaus auch automatische Updates möglich werden.
Einführung | Semantisches Web | Open Data | Anwendung in der Touristik | Anwendung bei sozialen Einrichtungen in Kommunen | Zukünftige Arbeit
Einführung
In den letzten Jahren hat die Open Data Bewegung an Fahrt aufgenommen. Um was es dabei gehen kann, habe ich z.B. hier beschrieben: Open Data: die nächste Runde und Open Data Institute (ODI): Open Data in a Day (deutsch ;-).
Ging es am Anfang hauptsächlich darum, dass die öffentliche Hand die Daten, die sie sowieso schon erhoben hat, für eine Zweitnutzung online zur Verfügung steht. Wenn man es mit einem modernen Transparenzgesetz wie in Hamburg macht, wo Daten a) grundsätzlich elektronisch zu halten sind (E-Akte) und b) grundsätzlich online zu veröffentlichen sind (solange sie keine personenbezogenen Daten sind oder sicherheitskritische), kommt man schnell zu der Frage, in welchem Format sie zu veröffentlichen sind. Tim Berners-Lee hat dazu ein Fünf-Sterne-Reifegradmodell entwickelt:
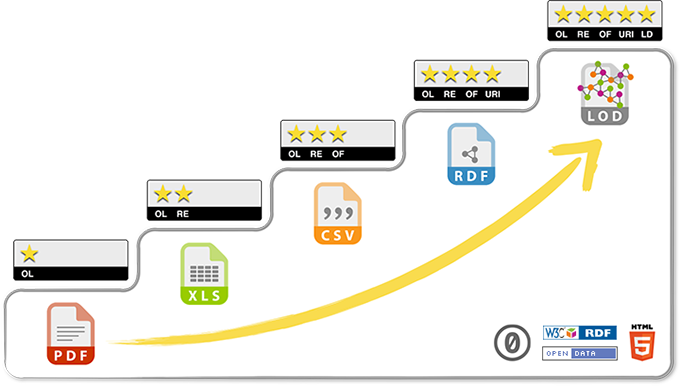 Abbildung 1 Fünf-Sterne Reifegradmodell nach Tim Berner Lee
Abbildung 1 Fünf-Sterne Reifegradmodell nach Tim Berner Lee
Einen Stern bekommt eine PDF-Datei (z.B. ein Protokoll einer Ratssitzung), zwei Sterne gibt es für eine Excel-Datei, die schon strukturiert, aber in proprietärem Format ist. Offener ist dann die CSV-Datei (Comma Separated Value) mit drei Sternen. Vier Sterne bekommen Daten im RDF-Format (Resource Description Framework). Hierbei wird dann einerseits beschrieben, wo eine Ressource zu finden ist und die ersten Schritte in die Semantik gegangen. Es wird definiert um was es dabei geht. Die volle Sternzahl bekommt ein Datensatz von Linked Open Data
Hier haben wir dann Daten (statt nur reiner HTML-Texte), die im Internet verlinkt sind, über http abrufbar sind und unterliegende Mechanismen wie RDF, SPARQL und die Web Ontology Language nutzen. Damit wird die Verarbeitung von Open Data durch Maschinen ermöglicht.
Ein einfaches Beispiel soll es verdeutlichen. Wenn man im Öffentlichen Personenverkehr Fahrplan- und IST-Daten über ein API veröffentlicht, dann muss man den Inhalt standardisieren. Es bedarf eine Seinskunde, einer Ontologie (Was ist ein Fahrplan? Was ist ein Bahnhof (geografisch)? und eine Taxonomie (wie sind die Daten aufgebaut, Syntax). Dies hat man bei dem internationalen Standard GTFS (General Transit Feed Specification). Damit kann man nun maschinenlesbar eine Fahrplan und Echtzeitdaten mittels eine APIs online stellen und andere können die Daten für Anwendungen nutzen (Routing: wie und wann komme ich von A nach B). Das hat in England erfolgreich die Firma TransportAPI gemacht:
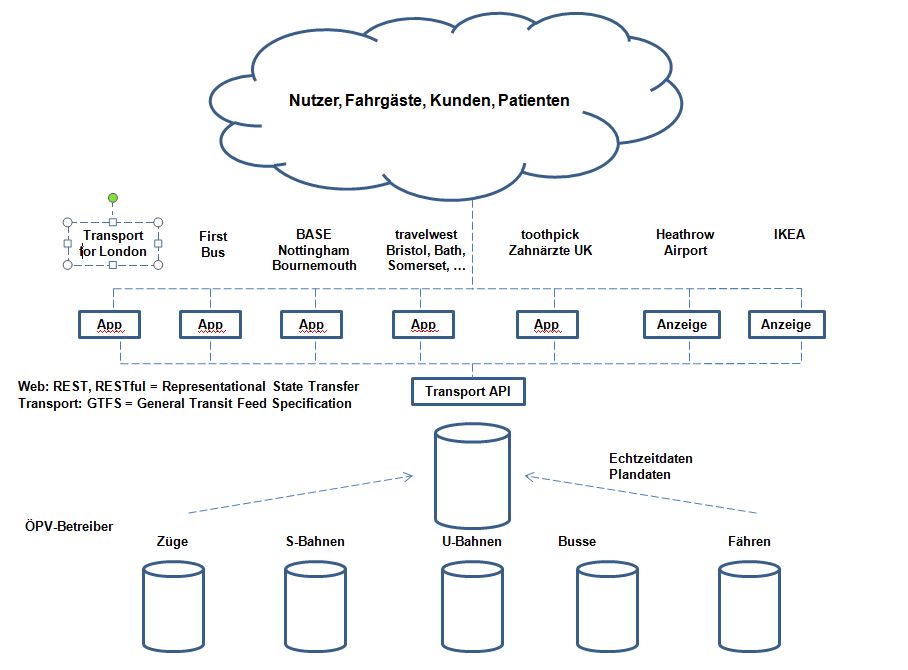 Abbildung 2 Datenfluss bei TransportAPI in London
Abbildung 2 Datenfluss bei TransportAPI in London
Als Klassendiagramm kann man GTFS so darstellen:
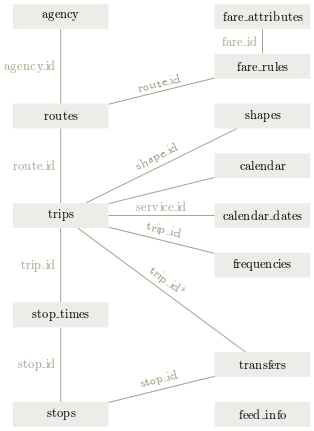 Abbildung 3 GTFS als Klassendiagramm (Gemeinfrei nach Wikipedia)
Abbildung 3 GTFS als Klassendiagramm (Gemeinfrei nach Wikipedia)
{kind=link}
Im Folgenden wird nun diskutiert, was semantische Webs sind und was das mit Open Data zu tun hat. In Beispielen aus dem Tourismus und sozialer Einrichtungen werden die Probleme pragmatisch beleuchtet. Zum Schluss wird dann diskutiert, was zu tun bleibt.
Semantisches Web
Das klassische Web kannte drei wichtige Standards, mit denen Tim Berner Lee das World Wide Web einführte:
- URLs (Uniform Resource Locator) für Adressen von beliebigen Dateien im Web,
- HTTP (Hypertext Transfer Protocol) als Protokoll, um diese Dateien abzurufen und
- HTML (Hypertext Markup Language) als Auszeichnungssprache für textuelle Dokumente.
Damit sind dann Zugriff, Transport und Textformat definiert, nicht aber der Inhalt oder die Bedeutung.
Time Berner Lee ergänzte diese dann mit seinem Vorschlag für ein semantisches Web, mit dem auch Ontologie und Taxonomie festgelegt werden. Formal definiert man den Aufbau dann heute so:
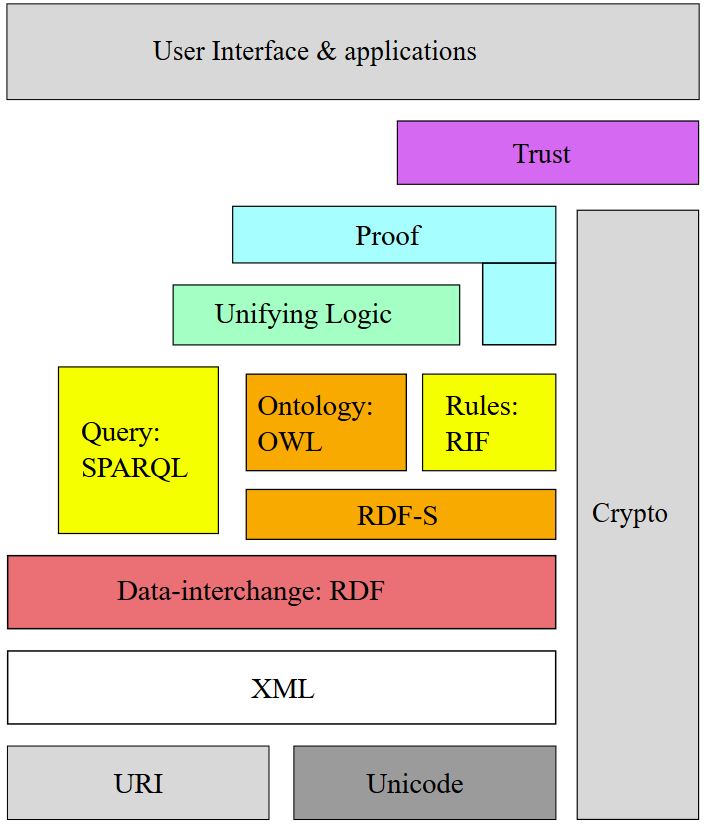
Abbildung 4 Semantisches Web Urheber: Von I, Mhermans, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=2291674
Von unten nach oben werden folgende Elemente standardisiert (nach Wikipedia):
- „URIs in der doppelten Rolle zur Identifizierung von Entitäten und zum Verweisen auf weitergehende Daten dazuRDF als gemeinsames Datenmodell zur Repräsentation von Aussagen
- RDFS zur Deklaration des Vokabulars, welches in RDF verwendet wird
- OWL zur formalen Definition des in RDFS deklarierten Vokabulars in einer Ontologie
- RIF für die Darstellung von Regeln
- SPARQL als Anfragesprache und -protokoll
- eine Reihe von verschiedenen Syntaxen um RDF-Graphen auszutauschen:
Diese Art von semantischen Webs haben in der Wirtschaft Verbreitung gefunden und werden an vielen Hochschulen weiter erforscht.
Open Data
Für Open Data der öffentlichen Hand liegen in der Regel noch keine Ontologien vor. Gerad auch in Deutschland ist die Vorgehensgeschwindigkeit recht klein. Folgt man dem Fünf-Sterne-Modell von Tim Berners-Lee geht es um 4 Sterne (RDF – Resource Description Framework) und 5 Sterne (LOD – Linked Open Data).
Im öffentlichen Bereich findet man häufig maschinenlesebare Open Data als Excel-Datei (*.xls, *.xlsx) vor oder als Comma-Seperated Value (*.csv). Um deren Inhalte zu erschließen, neigt man dazu wie früher in Bibliotheken für Bücher die Inhalte zu verschlagworten und einen Datenkatalog zu fühen, der mit den Objekten (Dateien) verbunden ist, nicht aber mit den Inhalten. Schon bei Kindertageseinrichtungen gibt es keine eindeutige Bezeichnung (Kindergarten, Kita, Kindertagesstätte national; child care international). Erst recht gibt es keine Ontologie, die standardisiert, welche Merkmale einen Kindergarten ausprägen (Postanschrift, Gauß-Krüger- oder UTM-Koordinaten, Telefonnummer, pädagogisches Konzept, Catering, Bausubstanz, Bewertung durch Eltern, Kosten für Eltern, Personalausstattung, etc., siehe z.B. auch meinen Artikel Open Data: die nächste Runde)
Hier soll es jetzt (noch) nicht darum gehen, Ontologien und Taxonomien für den öffentlichen Bereich (Public Service) vorzuschlagen, sondern nur in zwei Beispielsbereichen die Problematik zu beleuchten, um eine Diskussion anzustoßen: Touristik und soziale Einrichtungen.
Anwendung in der Touristik
Die Universität Florenz führt ein komplexes Semantic Web Projekt km4city durch. Die folgende Abbildung zeigt die verwendeten Elemente im Überblick. Details kann man sich auf deren Webserver ansehen.
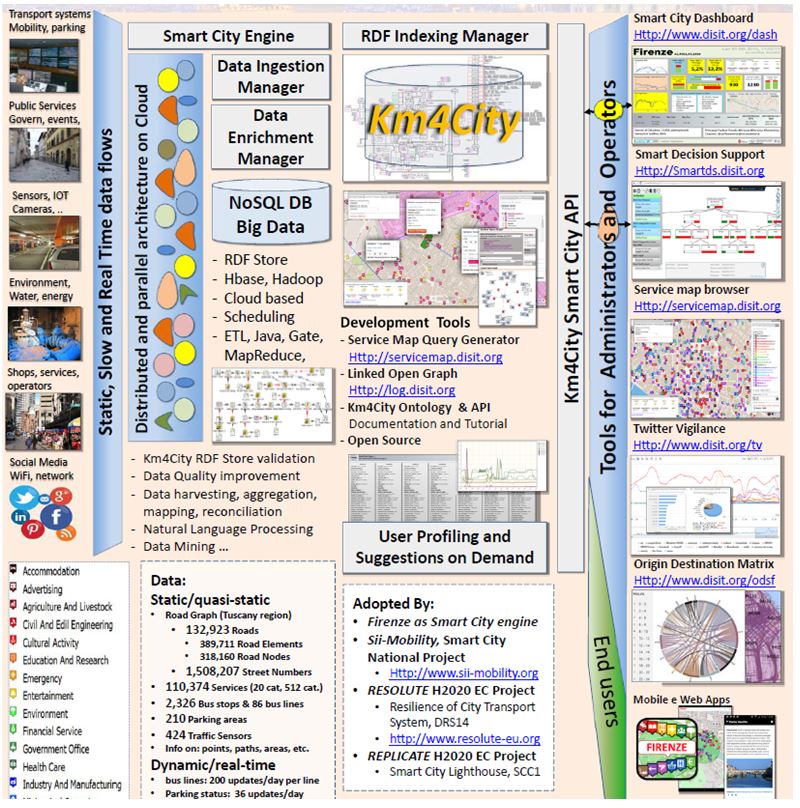
Abbildung 5 Projekt km4city, Florenz
Ein Teil dieses Projektes ist eine Karte (Open Street Map), auf der eine Vielzahl von Einrichtungen angeben sind. Über ein Auswahl Menu kann man wähl, welche Art von Objekten gezeigt werden. Eine Besonderheit ist es, dass man wie in Google Maps auch Verkehrsverbindungen an zeigen lassen kann. Ein Tourist kann also seine Visite planen, indem er aufzusuchende Objekte selektiert und sich dann z.B. Verkehrsverbindungen vom Bahnhof zum Duomo oder zum Rathaus oder zu den Uffizien oder zum Südufer des Arno anzeigen lässt (aber es fährt kein Bus über die Ponte Veccio 😉
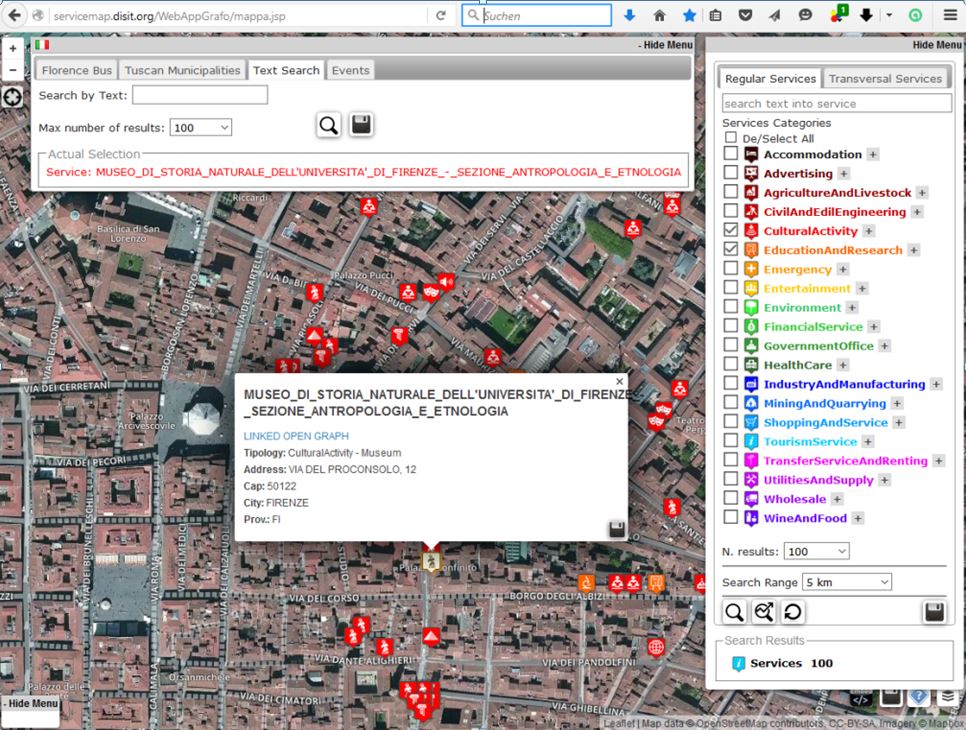 Abbildung 6 Karte aus dem Projekt km4city (Online-Quelle siehe hier)
Abbildung 6 Karte aus dem Projekt km4city (Online-Quelle siehe hier)
Allerdings ist die Detailtiefe gering. Nimmt man zum Beispiel die Kathedrale von Florenz (Duomo), so erfährt man nicht:
- dass dieses Meisterwerk aus der Renaissance ist (und eben nicht der Gotik. Siehe meine Artikel zur Gotik :-),
- dass die Kuppel, das Hauptwerk Brunelleschis, ein spektakuläres Bauwerk ist,
- dass Macciavelli, Dante Allighieri, Petrarca, die Stadt intellektuell geprägt haben und
- dass Dan Brown seinen Krimi „Inferno“ auch in der Kathedrale spielen lässt (siehe auch Film auf Youtube oder FAZ-Artikel zum „Krimi-Tourismus“).
Hier ist also eine Ontologie und Taxonomie aufzustellen: Was ist eine Kathedrale? Welche Elemente beschreiben sie (Architektur, Ausstattung, Geschichte, Literatur, siehe auch Glöckner von Notre-Dame in diesem Gotikartikel).Will man die Taxonomie so gestalten, dass man auch die Query „Welche kulturellen Bauwerke beschreibt Dan Brown in seinen Werken, z.B. in Rom, Florenz, Istanbul.“ beantworten kann?
Durch das Buch „Ich bin dann mal weg“ von Hape Kerkeling, das auch verfilmt wurde, hat der Jakobsweg (ein katholischer Pilgerweg) neue touristische Attraktion erfahren. Im Westen in Santiago de Compostela in Spanien endend wird er im Osten ständig erweitert, weil immer mehr Gegenden von dem Ruhm partizipieren möchten. So bietet es sich für Kommunen an, an denen der Jakobsweg vorbeiführt, touristische Informationen einfach bereitzustellen, so dass der Tourist schnell Sehenswürdigkeiten, Gaststätten, Unterkünfte und auch Verkehrsmittel erkennen kann. Eine solche Karte zu erstellen ist mit Google Maps eine Sache von wenigen Stunden. Das Beispiel in der Abbildung ist einem Artikel von mir entnommen und zeigt einen Ort am linken Niederrhein.
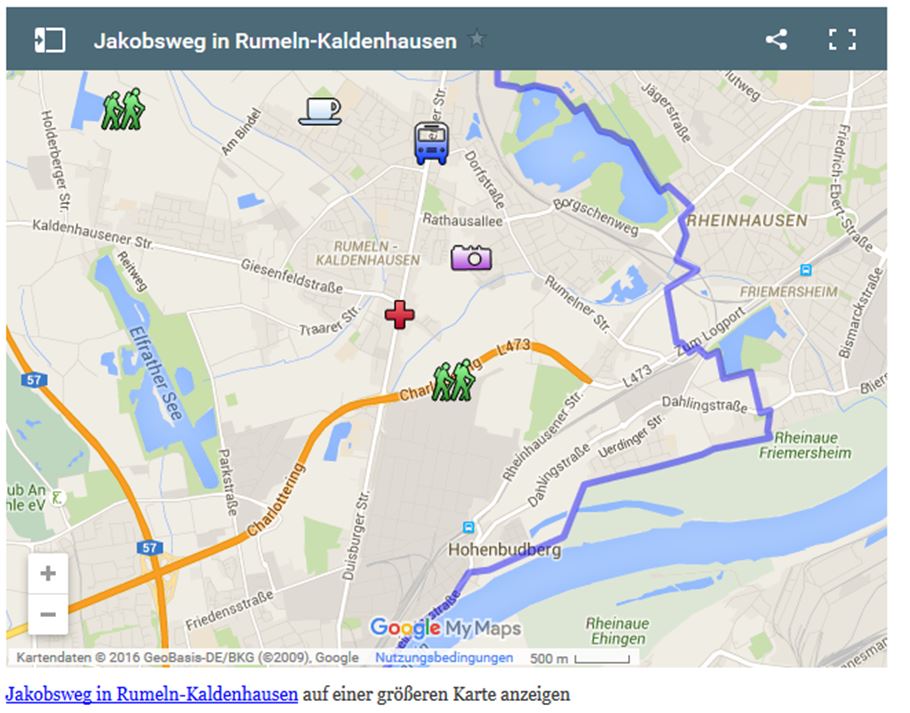 Abbildung 7 Jakobsweg in Rumeln
Abbildung 7 Jakobsweg in Rumeln
Aber auch hier stellt sich die Frage nach Ontologie und Taxonomie der abzubildenden Objekte. Womit will man die Marker auf der Karte attributieren, z.B. bei einem Restaurant: Adresse, Koordinaten, Telefon, Website (mit Speisekarte), Fotos, Öffnungszeiten? Die Abbildung zeigt ein Restaurant in Rumeln-Kaldenhausen mit einem Foto aus den 1970er Jahren, wenn man auf das Icon mit der Kaffeetasse klickt. Erwähnt sei auch, dass man mit Google Maps prinzipiell die Daten auch mit KML exportieren kann, um die Inhalte mehrere Seiten zusammenzuführen und andererseits die Einzelkarten einfach mit Excel pflegen und hochladen kann, um sie dann in einem Contenmanagement-System zu verlinken.
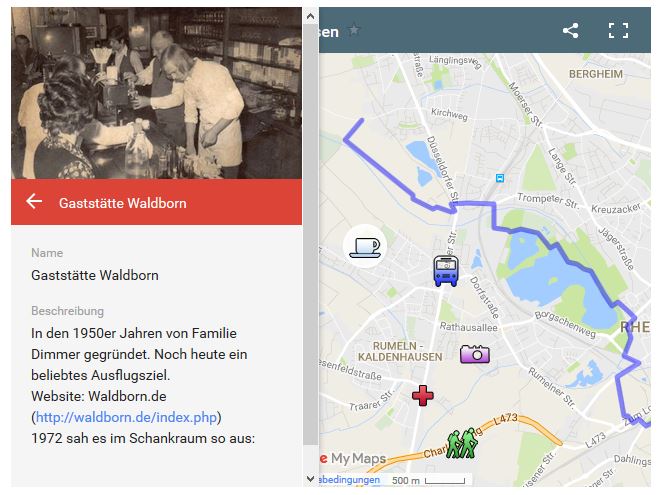 Abbildung 8 Gaststätte in Rumeln
Abbildung 8 Gaststätte in Rumeln
Denkt man z.B. an einen Touristikunternehmer, der All-Inclusive-Angebote erstellen will, hat der natürlich Interesse an standardisierten Daten entlang des ganzen Jakobweges und nicht nur in einer Kommune. Hier ist dann auch Internationalität gefordert, dass der Jakobweg durch Deutschland, Frankreich und Spanien führt. Tourismus ist ein Szenario, um Daten, die sowieso vorhanden sind, für andere Anforderungen zu aggregieren. Andere Szenarien kann man bei sozialen Einrichtungen nutzen.
Anwendung bei sozialen Einrichtungen in Kommunen
Szenarien helfen, den möglichen Nutzen von Maßnahmen besser auszuleuchten. Z.B. ein Umzugsszenario für eine Familie oder ein Ansiedlungsszenario für Unternehmen (siehe z.B. auch Einheitlicher Ansprechpartner bei EU-Dienstleistungsrichtlinie). Wenn z.B. eine Familie, mit zwei Kindern (5 und 9), zwei Eltern und einem Großvater umziehen, gibt es immer Informations-Bedarfe, der durch vorhandene Daten des Staates Überwiegend gedeckt werden kann. Die Auflistungen unten zeigen Objekte, für die die Familie Daten braucht, aber bisher noch keine standardisierten Ontologien und Taxonomien existieren. Trotz der relativ großen Mengengerüste von Umzügen.
 Tabelle 1 Objekte für Datennachfrage, -angebot und Mengengerüste
Tabelle 1 Objekte für Datennachfrage, -angebot und Mengengerüste
Die Stadt Bonn hat zum Beispiel in ihrem Open Data Portal eine CSV-Datei mit Kindertageseinrichtungen. Innerhalb kurzer Zeit lässt sie sich in Google Maps hochladen und als Karte darstellen, der Marker angeklickt werden können:
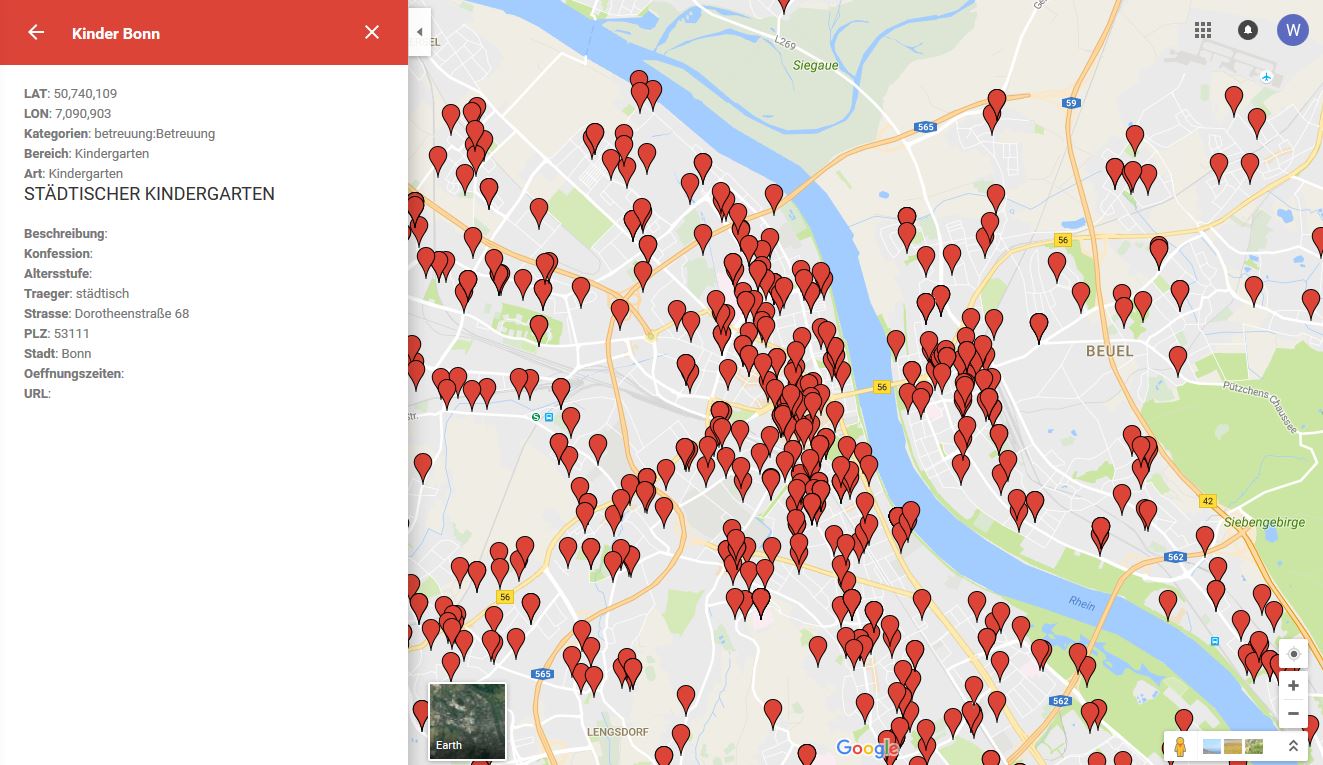 Abbildung 9 Kindertageseinrichtungen Bonn
Abbildung 9 Kindertageseinrichtungen Bonn
Der Vorteil eine Darstellung auf einer Karte ist für das obige Familien-Umzugsszenario, dass die Frage, welche Kita „in der Nähe“ einer Immobilie ist, sich mit einer Karte wesentlich einfacher beantworten lässt als mit einer Liste. Da aber in dem Szenario auch eine Schule und ein Pflegeheim gesucht wurde, wäre es hilfreich, wie in Florenz auch Selektoren zum Aktivieren zu haben.
Ist die Kommune nicht allzu groß, lassen sich die Objekte vielleicht auch auf einer Karte ohne Selektoren darstellen, wie es in der folgen Abbildung zu sehen ist aus dem Demobeispiel des Artikels „Google Maps mit Rumeln„, wie es auch in dem Artikel „Mehr Nutzen für Bürger und Wirtschaft – nicht nur beim eGovernment“ in der Zeitschrift eGovernment-Computing verwendet wurde.
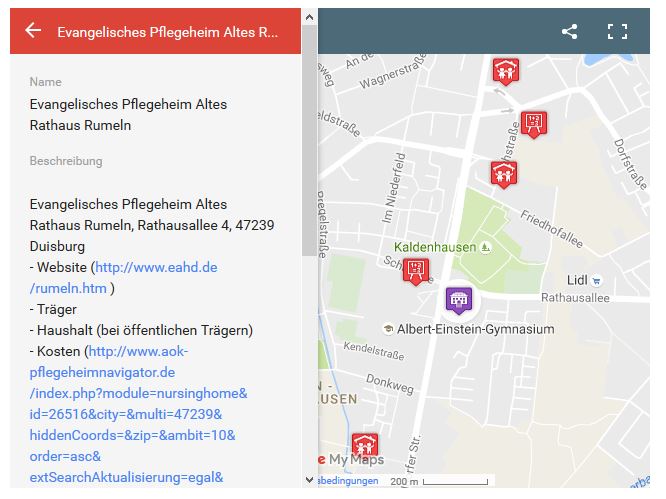 Abbildung 10 Soziale Einrichtungen in Rumeln-Kaldenhausen
Abbildung 10 Soziale Einrichtungen in Rumeln-Kaldenhausen
Der Nutzen von solchen Karten lässt sich wie folgt zusammenfassen:
Nutzen für den Bürger bzw. ähnlich für die Wirtschaft
- Der Bürger kann mit einem einfachen Interface (Karte und WWW) auf Daten des Staates zugreifen
- raumbezogenen Informationen müssen nicht in zahlreichen Systeme zusammengesucht werden
- Bei Umzügen und ständige Bewohner sind die Informationen aus der Nachbarschaft zusammen dargestellt
- Die Umgebung eines Wohnstandortes wird sofort transparent
- Alle Informationen, die der Staat mühselig sammelt, werden für bestimmte Zwecke zusätzlich nutzbar
- Durch Transparenz können Fehlinvestitionen vermeiden werden, z.B. Kauf eines Hauses zu überhöhtem Preis
- Durch Transparenz können “richtige“ Institutionen gewählt werden (z.B. Vermeidung von Schuljahreswiederholung durch „richtige“ Schule (Vermeidung von 100 T€ Lohnausfall im Arbeitsleben)
Nutzen für den Staat/die Kommune
- Kommunen können ihre Attraktivität direkt in einem eigenen Portal darstellen und durch ihre Abgabe ihrer KML-Daten oder anderer Formate ihre Reichweite durch andere Aggregatoren erhöhen
- Durch die Verwendung von Hyperlinks können bestehende Informationsquellen integriert werden, ohne eigene Anwendungen bauen zu müssen.
Neben den bisher schon beschriebenen Objekten, über die die öffentliche Hand zahlreiche Daten hat, die einer Zweitverwendung als Open Data zugeführt werden können, seien hier auch noch Umweltdaten genannt. Natürlich ist es wichtig bei der Immobiliensuche zu wissen, welche Umweltbelastung man einem Standort zu erwarten hat: Feinstaubbelastung, CO2, Lärm, Stickoxide, Schwefeloxide, usw.
Das letzte Beispiel soll zeigen, was passiert, wenn die Open Data-Community gar nichts macht. Es zeigt die Eingabe von „Kindergarten Manhattan“ in Google Maps. Man beachte die deutsche Schreibweise. Es werden eine Vielzahl von Objekte gefunden, die nicht alle Kindergärten sind, aber eben auch Kindergärten. Mit Foto, Adresse, Webadresse, Möglichkeit mit Streetview das Objekt von der Straße aus zu sehen. Wenn also Kommunen nicht von sich aus für sich werben, werden sie darauf angewiesen sein, dass Eltern und Unternehmen in Google ihre Suche unterstützen lassen. Sind die Kommunen dort richtig präsent?
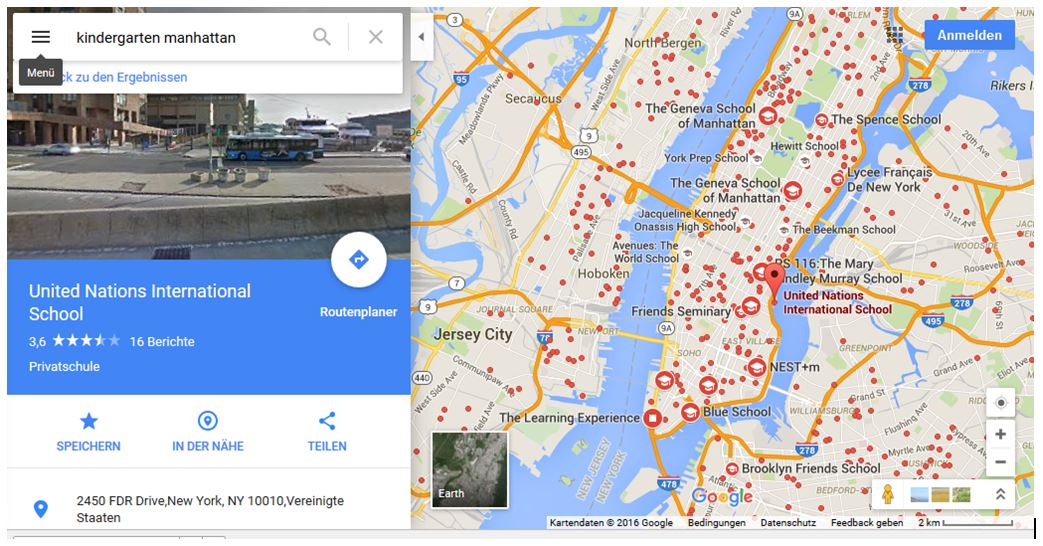 Abbildung 11 Google Maps Suche „Kindergarten Manhattan“
Abbildung 11 Google Maps Suche „Kindergarten Manhattan“
Zukünftige Arbeit
In der Zukunft werden also semantische Standards geschaffen werden müssen, um Open Data auch in Semantischen Webs repräsentieren zu können, damit auch Maschinen diese Daten verarbeiten können werden. Webserver mit unstrukturierten Daten in Excel- oder CSV-Format, die händisch katalogisiert wurden, ohne semantische Strukturierung des Inhalts der Dateien, reichen dazu nicht aus.
Hier also noch einmal eine plakative Erinnerung, die schon Martin Kaltenböck in seinem Workshop im Jahre 2013 zum Ausdruck brachte: eGovernment Konferenz 2013, Österreich – Workshop: Grundlagen und Mehrwerte von Linked Open Data (LOD):
 Abbildung 12 Was ist ein Kindergarten?
Abbildung 12 Was ist ein Kindergarten?
Hier ist nun dazu eine Tabelle für die Entitäten Kindergarten, Schule und Pflegeheim, welche Daten die öffentliche Hand kennt, die vielleicht als Open Data herausgegeben werden, um dem Bürger mehr Nutzen zu bereiten mit Daten, deren Erfassung es sowieso schon bezahlt hat (Eh-da-Daten = die Daten sind eh da).
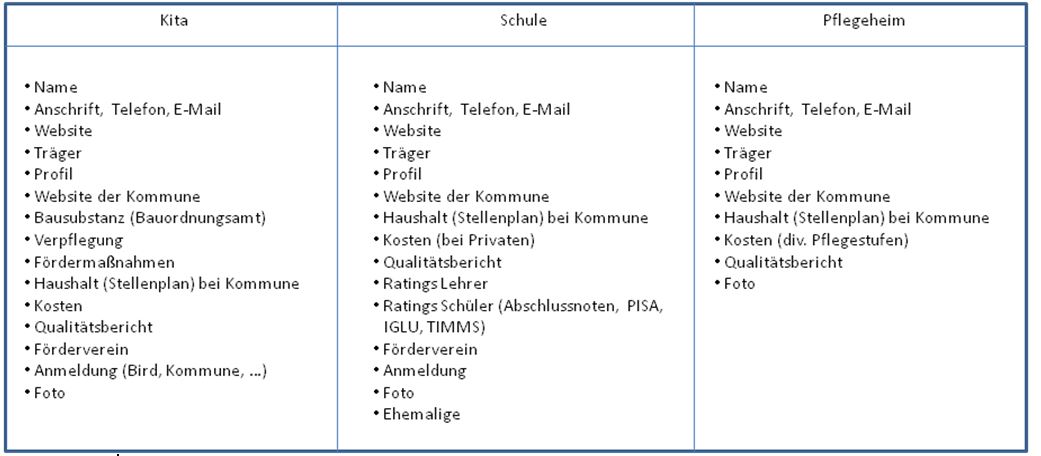 Tabelle 2 Merkmale von Kindergärten, Schulen und Pflegeheimen
Tabelle 2 Merkmale von Kindergärten, Schulen und Pflegeheimen
Die spannende Frage ist, wie man diese Merkmale strukturieren kann und standardisieren kann, damit auch diese Klassen von Open Data für ein semantisches Web nutzbar gemacht werden können und für Maschinen verarbeitbar werden.
Wer daran Interesse hat mitzuwirken, oder den Fortgang der Dinge finanzieren will, darf sich gerne bei mir melden. Die fünf Sterne von Tim Berners Lee müssen kommen. Wer sollte es machen, wenn nicht wir?