Will man neuere Möglichkeiten von Ausfallsicherheit und Skalierbarkeit in IT-Landschaften nutzen, so gelingt das leicht mit Kubernetes-Ökosystemen, die man bei einem Cloud-Service-Provider oder in einem eigenen Rechenzentrum (on Premise) einrichten kann. Der Artikel beschreibt, aus mehrjährigen Erfahrungen, wie man bestehende Anwendungen oder selbst erstellte auf ein Kubernetes-Ökosystem plant, welche Tools man noch braucht, welche „Middleware“ nötig ist und welche Cloud-Service-Provider (Hyperscaler oder DSGVO-kompatible Dienstleister) man nutzen kann.
Cloud-Technologie auch in Deutschland
Vor fast 10 Jahren schrieb ich einen Artikel „Governance und Compliance beim Cloud Computing“. Damals kam ich zu dem Schluss, dass man Clouds nutzen können, da auch US-Ministerien ihre Mails bei Google und Microsoft in die Cloud legten und Dataport in Hamburg erfolgreich den Code von Microsoft365 getestet hatten, um ihn datenschutzkonform in der eigenen Private Cloud zu nutzen.
Doch das BMWi legte sich quer, in dem es mit dem Projekt Trusted Cloud fünf Jahre den Markt in Deutschland blockierte. Heute firmiert es als Verein (Bundesdruckerei u.a.) und stört den Markt nicht mehr. Statt dessen hat sich die Cloud-Nutzung massiv verbreitet, zunächst durch Hyperscaler aus USA und China, zunehmend durch europäische Anbieter.
Hier soll nun ein kurzer Überblick gegeben werden, wie man Cloud-Strategien technisch entwickeln kann. Die folgende Abbildung gibt eine Gesamtübersicht, die im Folgenden dann im Detail besprochen wird.
Die folgende Abbildung gibt eine Gesamtübersicht, die im Folgenden dann im Detail besprochen wird.
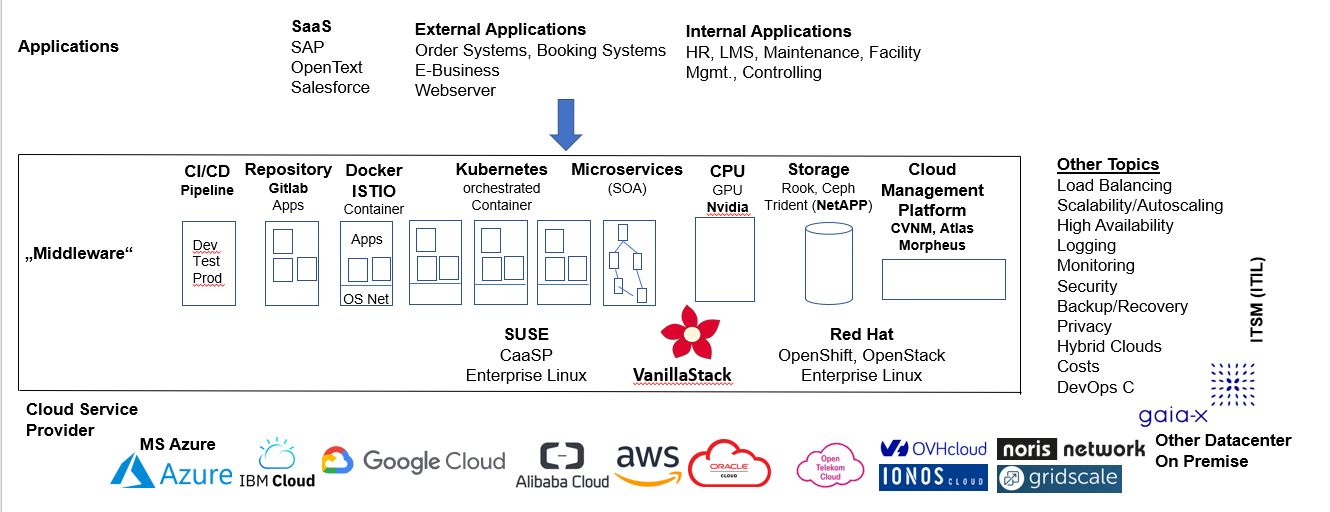 Drei Ebenen sieht man hier.
Drei Ebenen sieht man hier.
Ebene 1 Anwendungsebene
In der Ebene Applications findet man:
- Software as a Service wie SAP, Open Text oder Salesforce, die man alle fix und fertig in der Cloud buchen kann.
- Anwendung für Externe: Eigene bestehende Anwendungen können Order-Systeme, Booking-Systeme (Airline, Bahn), sonstige E-Business-Systeme sein.
- Für die interne Anwendungen können HR-Systeme, Lernmanagement-System, Wartungssysteme (Maschinen, Fahrzeuge), Facility-Management-Systeme, Controlling usw. sein.
- Selbst programmierte Applikationen können z.B. als Microservices über eigene CI/CD Pipelines integriert werden.
Ebene 2 Cloud-Ebene „Middleware“
Diese Ebene soll für Skalierbarkeit und Ausfallsicherheit in ein Kubernetes-Ökosystem sorgen. Anfangs werden Programme aus Repositories geladen und in einem Container (Docker oder Istio) isoliert bereitgestellt.
Kubernetes managet anschließend den Start einzelner Container. Z.B kann man sagen: starte morgens drei identische Container, die du dann über einen Loadbalancer gleichmäßig mit Last beaufschlagt. In den Peakzeiten der Nutzernachfrage füge weitere drei Container hinzu. Hier ist dann Logging wichtig, ob sich meine Annahmen als richtig erweisen. Habe ich zu wenig Container, kommt es zu Wartezeiten; habe ich zu viele Container alloziert, bezahle ich zu viel bei meinem Provider. Mit einer effizienten Skalierung durch den Loadbalancer können hier unnötige Kosten gespart werden.
Storage muss außerhalb der Container (Rook, Ceph, Trident, S3 usw.) bereitgestellt werden, um die Daten persistent zu halten und um parallele Instanzen zu synchronisieren. Container selbst speichern keine Daten und verlieren sämtliche gespeicherte Laufdaten bei ihrer Abschaltung.
Eine CI/CD-Pipeline (Development, Test, Produktion) kann zur Eigenentwicklung genutzt werden mit Ansible oder Jenkins. Eigene Binaries können wie fremde Binaries in ein Repository (z.B. Gitlab) geladen werden, um Programme zur Startzeit von Container dann daraus zu laden.
Für rechenintensive Prozesse können Graphic Processing Units (GPUs) z.B. von Nvidia in Kubernetes-Ökosysteme integriert werden.
Weitere Cloud Management Software kann genutzt werden.
Diese Elemente werden alle auf z.B. kommerzielle Software von Suse oder Redhat oder auf Open Source Software wie VanillaStack gesetzt. In VanillaStack sind zum Beispiel alle oben aufgeführten Tools als Open Source enthalten und auch die unten aufgeführten.
Other Topics
Hinzu kommen softwareseitig noch Programme für Load Balancing, Scalability/Autoscaling, Hochverfügbarkeit (z.B. zwei entfernte RZs mit in Echtzeit gespiegelten Daten), Monitoring, Backup/Recovery. Hervorgehoben seien:
- Security: Wer darf (vom Internet her) an Software heran? Benutze ich NAT (Network Address Translation), um andere Rechner zu schützen? Reverse Proxys? Firewalling?
- Privacy: Ganz wichtig ist in Deutschland bei der Verarbeitung personenbezogener Daten (nicht bei IoT-Daten ohne Personenbezug) die Einhaltung der DSGVO. Das können US Hyperscaler wegen des Cloud Acts, in dem die US-Regierung US-Unternehmen zwingt gegen europäisches Recht Daten mit Personenbezug im europäischen Rechtsgebiet herauszugeben, nicht ausreichend erfüllen.
- Kosten: Kostenstrukturen können kompliziert sein. Z.B. vorbestellte Knoten vs. Allozierung on Demand, sind die vorbestellten Knoten wirklich genutzt worden? Deshalb ist Monitoring zur Kostenkontrolle eminent wichtig bei variablen Tarifen.
- Hybride Clouds: als Beispiel kann es wichtig sein, für die CPU-Last Cluster bei einem Cloud-Service-Provider zu nutzen und für die Datenspeicherung vorhandene Storage-Devices in bestehenden RZ zu nutzen. Auch kann es sein, dass man Investitionen in eigene Storage-Systeme länger nutzen will, da man die Systeme nicht in das Cloud-RZ mitnehmen kann oder will.
- Scalabilty/Autoscalabilty: Es ist wichtig ein Ökosystem zu haben welches nach Last skaliert. Das kann fest eingestellt sein oder auch nach IST-Auslastung der Knoten automatisch erfolgen, dass man z.B. aber ab 75% Auslastung die automatische Hinzunahme weiterer Knoten triggert.
Sonderfälle
Die obigen Ausführungen beschreiben wie man „eine“ Cloud nutzen will, kommen weitere Fälle hinzu:
- Ausfallsicherheit/Spiegelung: Hier muss man entscheiden, ob man seine Architektur an einem weiteren Standort spiegeln will und auf welcher Ebene die Spiegelung erfolgen soll. Zum Beispiel. eine in Echtzeit gespiegelten Datenbank, die beiden parallel arbeiten über Loadbalancing oder ob bei einem Ausfall des einen Systems das andere die Arbeit übernehmen soll.
- Edge Computing: Hier können beispielsweise viele autonome System weit verstreut an den „Ecken“ der Cloud stehen, Daten sammeln und lokal (vor-)verarbeiten und sie dann zentral übermitteln, weil man aus den technischen Daten kaufmännische Rechnungen generieren will. Durch die dezentrale Verarbeitung an der Ecke kann Bandbreite gespart werden.
- Multicloud: Es kann sein, dass Datensammlungen von mehreren Organisationen genutzt werden sollen. Zum Beispiel müssen Energieversorger nach Redispatch 2.0 ihre Kohlekraftwerke abschalten, wenn genügend Wind- und Solarenergie vorhanden ist. Dafür will man natürlich sehr früh aus gemeinsamen Daten wissen, ob ausreichend Energie aus nachhaltigen Quellen im Netz vorhanden ist.
Ebene 3 Cloud Service Provider
Wenn man dann einen Plan hat, wie man seine Anwendungslandschaft in Clouds implementieren will, benötigt man einen Cloud-Service-Provider. Da findet man dann Microsoft Azure, IBM Cloud, Google Cloud Platform, Alibaba Cloud, Amazon AWS, Oracle Cloud, wobei die US Hyperscaler wegen des Cloud Actes für personenbezogene Daten ohne DSGVO-Compliance nicht nutzbar sind. Europäische Anbieter wie OVHcloud, noris network, Ionos Cloud haben keine Datenschutzprobleme und können somit in Europa für personenbezogene Daten genutzt werden.
Die Cloud Service Provider die DSGVO-compliant sind, werden wahrscheinlich ab Anfang 2022 bei Gaia-X zu finden sein. Dort wird man dann im Katalog sagen können: ich brauche 30 Knoten, soviel Memory und soviel Storage. Man bekommt dann eine Liste zertifizierter Anbieter und auch Preise, was den Wettbewerb ankurbeln wird.
Conclusio
Auch in Deutschland ist das Cloud-Zeitalter angebrochen. Nicht nur große Unternehmen, sondern auch Staat und kleine und mittlere Unternehmen können Cloud-Technologie günstig und sicher nutzen, auch im europäischem Rechtsrahmen mit DSGVO und ohne Cloud Act. Die Ausführungen zeigen auch, dass die Nutzung nicht ganz trivial ist und in den IT-Abteilungen ggf. Anwendungen und Infrastrukturen besser getrennt sollten, aber viele der oben beschriebenen Aufgaben sind heute auch teilautomatisiert darstellbar. Diese Entwicklungen bedeuten aber auch Erleichterung für Organisationen, deren Kerngeschäft nicht IT-Betrieb ist, also die meisten.
Kommentare sind wegen zu viel Aufwand nach DSGVO deaktiviert. Mail gerne an wk@wolfgang-ksoll.de